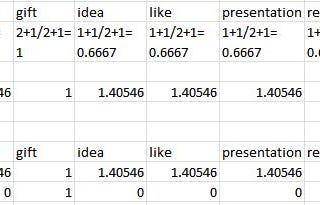
Yash JoshiVectorization-Converting text to numbersWhen you are done with text cleaning then the next important step is to convert the text data to numbers, as the machine understands…5 min read·Dec 29, 2020----
Yash JoshiInvest a part of your time in critical thinkingWhat’s your first reaction when you are given a problem? Well, you will go through the problem statement and try to be responsive with…4 min read·Jul 22, 2020----
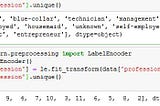
Yash JoshiData Pre-processing before model trainingYou got a data-set and you’re ready to start with model training and predictions, but wait! Is this data ready to train the algorithm…5 min read·Jul 14, 2020----